一、webpack和 router
webpack:
是什么?
webpack可以看做是模块打包机,它主要做的事情是分析项目的结构,找到JavaScript模块以及其他的一些浏览器不能直接运行的扩展语言(sass和ts等),并将其装换和打包为合格的格式供浏览器使用。
打包原理:
把一切都视为模块,不管是css,js还是image和html都可以相互引用,通过定义entry.js,对所有依赖的文件进行跟踪,将各个模块通过loader和plugins处理,然后打包在一起。
基本功能:
- 代码转换:Typescript–>JavaScript;SCSS->CSS等。
- 文件优化:压缩js,css,html代码,压缩合并图片。
- 代码分隔:提取多个页面的公共代码。
- 模块合并:在采用模块化的项目有很多模块和文件,需要构建功能把模块分类合并成一个文件。
- 自动刷新:监听本地源代码的变化,自动构建,刷新浏览器等。
- 代码校验:在代码被提交到仓库前需要检测代码是否符合规范,以及单元测试是否通过。
- 自动发布:更新代码之后,自动构建代码。
router:
路由库用于在浏览器中处理URL路径,并根据路径匹配显示不同的内容,而无需每次都要加载新的HTML页面。
常见的路由库:
- Vue Router
- React Router
- React Navigation
使用路由库,一般需要考虑的因素:
- 路由的定义
- 导航
- 路由参数
- 嵌套路由
二、利用路由跳转到下一个页面的方式有哪几种?
-
使用链接a标签
1
| <a href='/next-page'>下一个页面的链接</a>
|
-
编程式导航
1
2
3
4
5
6
7
8
9
10
11
12
|
import {useHistory} from 'react-router-dom';
function MyComponent(){
const history=useHistory();
function handleToNewPage(){
history.push('/next-page');
}
return <button onClick={handleToNewPage}>跳转到另一个页面</button>
}
this.$router.push('/next-page');
|
-
声明式导航
1
2
3
4
5
6
7
8
9
|
import {Link} from 'react-router-dom';
....
<Link to="/next-page">下一个页面</Link>
....
<router-link to='/next-page'></router-link>
|
三、跳转路由组件如何销毁?
1
2
3
4
5
6
7
8
9
|
class MyComponent extends React.Component{
componentWilUnmount(){
}
return(){
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import React,{useEffect} from 'react';
function MyComponent(){
useEffect(()=>{
return ()=>{
};
},[])
.....
}
|
1
2
3
4
5
6
7
8
9
10
11
12
| //Vue中销毁组件会触发beforeDestory钩子函数
<template>
//组件模板
</template>
<script>
export default{
beforDestory(){
//销毁组件执行的一些操作
}
}
</script>
|
在这些生命周期函数和钩子函数中,可以执行一下清理操作,例如取消订阅,消除定时器,释放资源等。
四、react函数式组件和类式组件的区别
组件的定义:
1
2
3
4
5
6
|
class MyComponent extends React.Component{
render(){
return <h1>类式组件</h1>
}
}
|
1
2
3
4
5
6
7
8
|
function MyComponent(){
return <h1>函数式组件</h1>
}
const MyComponent=(props)=>{
return <h1>函数式组件</h1>
}
|
state的定义,读取和修改方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
constructor(props){
super(props);
this.state={count:0};
}
<span>{this.state.count}</span>
this.setSate((state,props)=>({
count:state.count;
}))
this.setState({count:2});
|
1
2
3
4
5
6
7
|
const [count,setCount]=useState(0);
<span>{count}</span>
<button onClick={()=>setCount(count+1)}>修改state</button>
|
生命周期函数:
1
2
3
4
5
6
7
8
9
10
11
|
componentDidMount(){
}
componentDidUpdate(){
}
componentWillUnmount(){
}
|
关于this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
class MyComponent extends React.Component{
render(){
return <span>{this.props.name}</span>
}
}
class MyComponent extends React.Component{
handleClick=()=>{
console.log(this);
}
render(){
return <button onClick={this.handleClick}>点击</button>
}
}
class MyComponent extends React.Component{
constructor(props){
super(props);
this.handleClick=this.handleClick.bind(this);
}
handleClick(){
console.log(this);
}
render(){
return <button onClick={this.handleClick}>点击</button>
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
function MyComponent(props){
return <span>{props.name}</span>
}
function MyComponent(props){
function handleClick(e){
}
return <button onClick={handleClick}>点击</button>
}
|
五、路由已经跳转,前一个页面的请求还没有结束怎么办?
在VUE中,如果路由已经发生跳转,但是前一个页面的请求还没有结束,可以在组件的销毁钩子中取消未完成的请求,可以在beforeRouteLeave导航守卫中进行处理,例如:
1
2
3
4
5
6
| beforeRouteLeave(to,from,next){
this.$axios.cancelRequest();
next();
}
|
在React中,可以使用componentWillUnmount生命周期方法来处理组件即将被销毁时的逻辑,包括未完成的请求。如果使用的是函数式组件,可以使用useEffect钩子来模拟componentWillUnmount的效果。
1
2
3
4
5
6
7
8
9
|
class MyComponent extends React.Component{
componentWillUnmount(){
this.cancelRequest();
}
}
|
1
2
3
4
5
6
7
8
9
10
|
function MyComponent(){
useEffect(()=>{
return ()=>{
cancelRequest();
}
},[]);
}
|
| hash模式 |
history模式 |
| 有#号的 |
无#号 |
| 能够兼容到IE8 |
只能兼容到IE10 |
| 不需要在服务器层面上进行任务处理 |
每访问一个页面都需要服务器进行路由匹配生成html文件再发送响应给浏览器,消耗服务器大量资源 |
| 刷新不会出现404问题 |
会出现404问题 |
| 不需要服务器做任务配置 |
需要在服务器配置一个回调路由 |
更加推荐hash模式的理由:
- 网络模式角度分析:hash模式,地址改变时通过hashchange事件,只会读取hash符号后的内容,不会发起任务网络请求;但是history模式每访问一个页面,都会发起对服务器的请求。
- 服务器配置角度:hash模式下,服务器不需要任务配置。
七、ES6说一下,map和weakmap的区别。
ES6中,map和weakmap是两种不同的数据结构,但是都可以用来存储键值对。
Map:
- 特点:Map是一种键值对的集合,其中的键可以是任何数据类型,包括基本数据类型和对象引用。
- 内存管理:Map中对键的引用是强引用的,即便这些键是对象,只要Map存在,这些键所引用的对象就不会被垃圾回收。
- 遍历:Map对象的顺序与插入顺序有关。
- API:Map提供的相关API比较丰富,比如set、get、delete、has等。
1
2
3
4
5
6
7
8
9
10
11
|
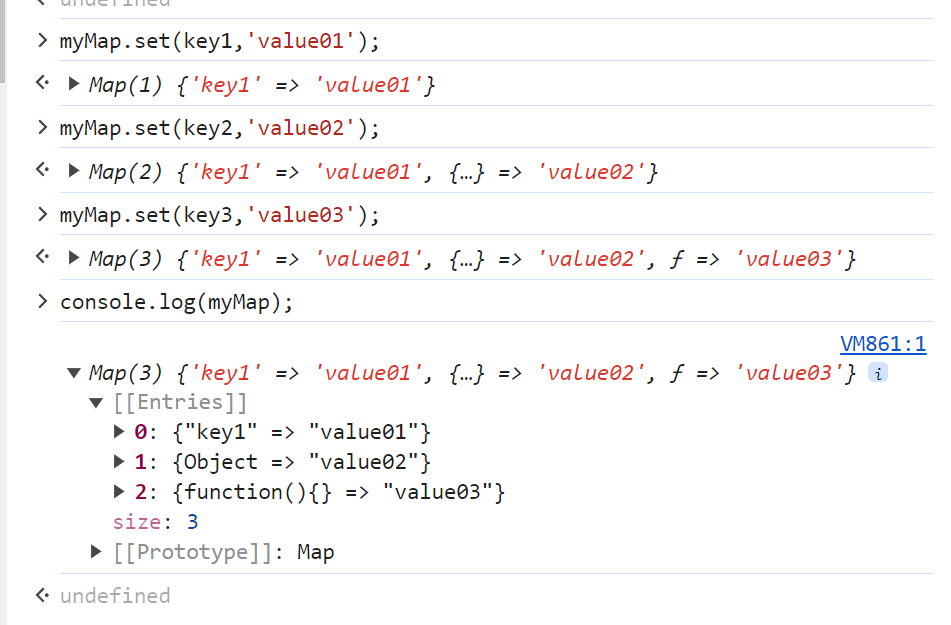
let MyMap=new Map();
let key1='key1';
let key2={};
let key3=function(){};
MyMap.set(key1,'value01');
MyMap.set(key2,'value02');
MyMap.set(key3,'value03');
console.log(MyMap);
|
WeakMap:
- 特点:weakmap同样也是一种键值对的集合,但是其中的键必须是对象。键是弱引用的,如果键的对象被垃圾回收了,则对应的值也会被自动移除。
- 内存管理:由于键是弱引用的,当键对象被垃圾回收时,与之关联的值也会被自动移除。
- 遍历:weakmap不支持遍历和获取其长度。
- API:Weapmap提供了set,get,delete,has等方法,但是不支持size方法。
1
2
3
4
5
6
7
8
9
10
|
let myWeakmap=new WeakMap();
let key={};
let value='value01';
myWeakmap.set(key,value);
console.log(myWeakmap.get(key));
key=null;
console.log(myWeakmap.get(key));
|
八、强引用和弱引用
|
强引用 |
弱引用 |
| 定义 |
当一个对象具有强引用时,即便是系统内存紧张,垃圾回收器也不会回收该对象。 |
与强引用反之。当一个对象具有弱引用时,垃圾回收器可以在合适的时机回收该对象,即使内存并不紧张。 |
| 示例 |
js中一般创建的对象通常是强引用的。 |
在js中,weakmap或weakset可以创建弱引用对象。 |
| 生命周期 |
强引用会延长对象的生命周期,直到所有的该对象的强引用都被释放为止。 |
而弱引用不会阻止对象被垃圾回收器回收。 |
| 内存管理 |
保存在内存中,直到所有该对象的强引用都被释放。 |
弱引用对象允许对象在没有强引用时被回收,从而更灵活地管理内存。 |
| 应用场景 |
全局变量,对象属性或是闭包 |
缓存,临时数据结构(当对象不再被需要时就会被回收) |
九、说说Symbol
Symbol是ES6中新引入的一种基本数据结构(字符串String,数字Number,布尔值true/false、空值null、未定义undefined、大数bigInt、Symbol),它的特点是:
1
2
3
| 1.Symbol的值是唯一且不变的。
2.Symbol的值不能与其他类型的数据一起运算。
3.Symbol定义的对象属性不能使用for...in来循环获取,但是可以Reflect.ownKeys(obj)来得到。(Reflect.ownkeys()返回一个数组,内容是传入对象的属性的键值)
|
Symbol的使用场景有:
- 作为对象的属性名。由于Symbol的值是唯一的,所以Symbol定义的对象属性可以防止属性的重复。
- 定义常量,保证常量的唯一性。
十、性能优化
前端一些常见的性能优化方法有:
- 压缩和合并资源:使用工具压缩css、js和图片等静态资源的大小,从而加快加载速度。将多个css文件或是js文件合并为一个文件,减少http请求次数。
- 使用CDN(内容分发网络):将静态资源部署到CDN上,以便用户可以从距离更近的服务器上获取到资源,加快渲染速度。
- 图片延迟加载和按需加载:在页面滚动时才加载图片,减少初次加载的时间。使用懒加载或是按需加载技术,只加载需要的组件和资源。
- 缓存:合理使用浏览器缓存,减少重复的网络请求和避免重复计算。
- 框架和依赖库的优化:只按需引用依赖库,使用虚拟DOM的框架(vue或react)来减少对真实DOM的操作。
- 前端代码的写法优化:避免频繁操作DOM,减少页面的重绘。将不影响页面初始加载的脚步改为异步加载,避免阻塞。
- 服务端优化:优化服务端配置和代码,加快响应速度。
十一、css文件加载过程中出现了阻塞会怎么样,加载html文档10ms,加载css20s会出现什么现象?
- 延迟页面渲染。由于css文件渲染阻塞了页面的渲染,浏览器将等待css文件加载完成之后才开始渲染页面内容。这就意味着用户会在20s后才能看到页面内容。
- 无样式内容闪烁(FOUC)。在css加载完成之前,页面会先以无样式的形式显示出来,当css加载完成后再渲染样式。这样会导致页面内容在没有样式的情况下闪烁,给用户带来的体验不佳。
- 阻塞后续资源加载。由于css文件加载阻塞了渲染进程,后续的资源加载(例如js文件,图片等)也会被延迟。
- 用户体验下降。长时间的阻塞可能会导致网站用户流失,给网站产生负面影响。
十二、html中的标签dl,dt和dd是什么意思?ol和ul呢?
1
2
3
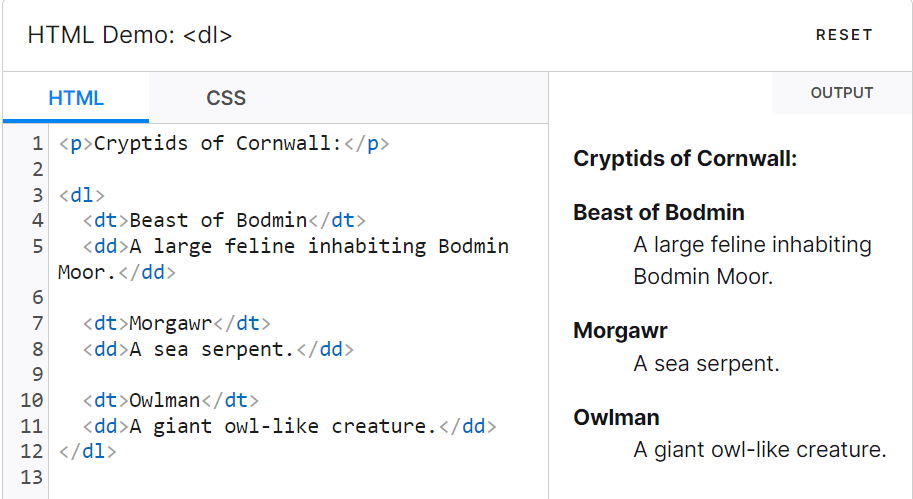
| <dl>:定义列表的开始标签,用于包裹一组术语及其定义。
<dt>:定义术语,用于标记定义列表中的术语或名词。
<dd>:定义描述,用于标记定义列表中的术语的描述或是定义、
|
1
2
| <ul>:无须列表,用于创建没有特定顺序的列表。
<ol>:有序列表,列表项使用数字或是字母进行标记。
|
十三、http1.1的Keep-Alive
HTTP1.1 Keep-Alive是对TCP连接的折中使用,既不是短连接,也不能称为典型的长连接,官方称为持久连接,
HTTP协议采用请求-应答模式,有普通的非KeepAlive模式,也有KeepAlive模式。
非KeepAlive模式下,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP称之为无连接的协议);反之,当KeepAlive模式下,客户端和服务器端的连接持续有效,当服务器出现后续请求时,KeepAlive模式会避免重新建立连接。
十四、http1.1和http2.0的区别
|
http1.1 |
http2.0 |
| 性能 |
1.1版本需要为每个请求建立独立的连接。 |
2.0版本支持多路复用,允许多个请求和响应在同一个连接上同时进行,所以这也意味着需要更多的网络资源。 |
| 头部压缩 |
1.1版本中,每个请求和响应的头部信息都需要进行重新传输,会造成一定的资源浪费。 |
2.0版本使用了头部压缩,通过使用索引和对重复头部的处理,减少数据传输时的开销。 |
| 服务器推送 |
1.1版本没有服务器推送的机制,所有的资源都需要等待客户端请求之后才能被发送。 |
2.0版本支持服务器推送,服务器可以在客户端请求之前主动将相关资源推送给客户端,从而减少客户端请求的延迟。 |
| 二进制分帧 |
1.1版本使用文本格式 |
2.0版本使用二进制来传输数据,二进制格式的优势在于更高效的解析和传输,从而提高了性能。 |
十五、http1.1中的keep-alive和http2.0中的多路复用的区别?
http1.1的keep-alive:
在HTTP/1.1中,keep-alive是一种持久的连接机制,允许在单个TCP连接上发送多个HTTP请求和响应。这种机制通过在请求头或响应头中包含connection:keep-alive来实现,以指示客户端和服务器保持连接,以便在同一个连接上发送多个请求。然而,即使是使用了keep-alive模式,每个请求或响应仍然需要按顺序进行,不能同时进行。
http2.0中的多路复用:
http2.0中的多路复用允许在单个TCP连接上并行发送多个请求或响应,从而避免了http/1.0中的阻塞问题。这意味着,多个请求和响应可以同时在同一个连接上进行,而不需要按照顺序进行等待,这种并行处理提高了网络利用率和页面加载速度。